Article
IA Multimodal en Medicina: De la Visión al Lenguaje y el Futuro de la Patología Digital
IA Multimodal en Medicina: De la Visión al Lenguaje y el Futuro de la Patología Digital Autor: Dr. Andric Guerrero E. MD. Pathologist | AI Scientist | Digital & Computational Pathology andricpath.com

Introducción
La inteligencia artificial ha dejado de ser una herramienta de procesamiento unidimensional para convertirse en un sistema multimodal capaz de integrar diversos flujos de información. En el ámbito clínico, los Vision-Language Models (VLM) representan la vanguardia, permitiendo que una máquina no solo "vea" una imagen médica, sino que entienda su significado semántico para describir hallazgos, responder preguntas diagnósticas o buscar casos similares en bases de datos masivas
1. Arquitecturas Fundamentales: Alineamiento vs. Generación
Existen dos grandes familias de modelos que dominan el panorama actual de la IA multimodal:
Modelos de Alineamiento (Embeddings compartidos): Estos modelos, como CLIP (Contrastive Language-Image Pre-training) y SigLIP, conectan imágenes y texto en un mismo espacio vectorial. Su objetivo es que los pares correctos (ej. una Rx de tórax y su reporte) queden "cerca" matemáticamente, mientras que los pares incorrectos se alejen. Son ideales para tareas de retrieval (búsqueda de casos) y clasificación zero-shot.
Modelos Generativos (Visual Question Answering y Razonamiento): Aquí, la imagen se convierte en tokens que un modelo de lenguaje (LLM) procesa para generar texto libre. Modelos como BLIP-2, Flamingo y LLaVA permiten una interacción conversacional con los datos médicos.
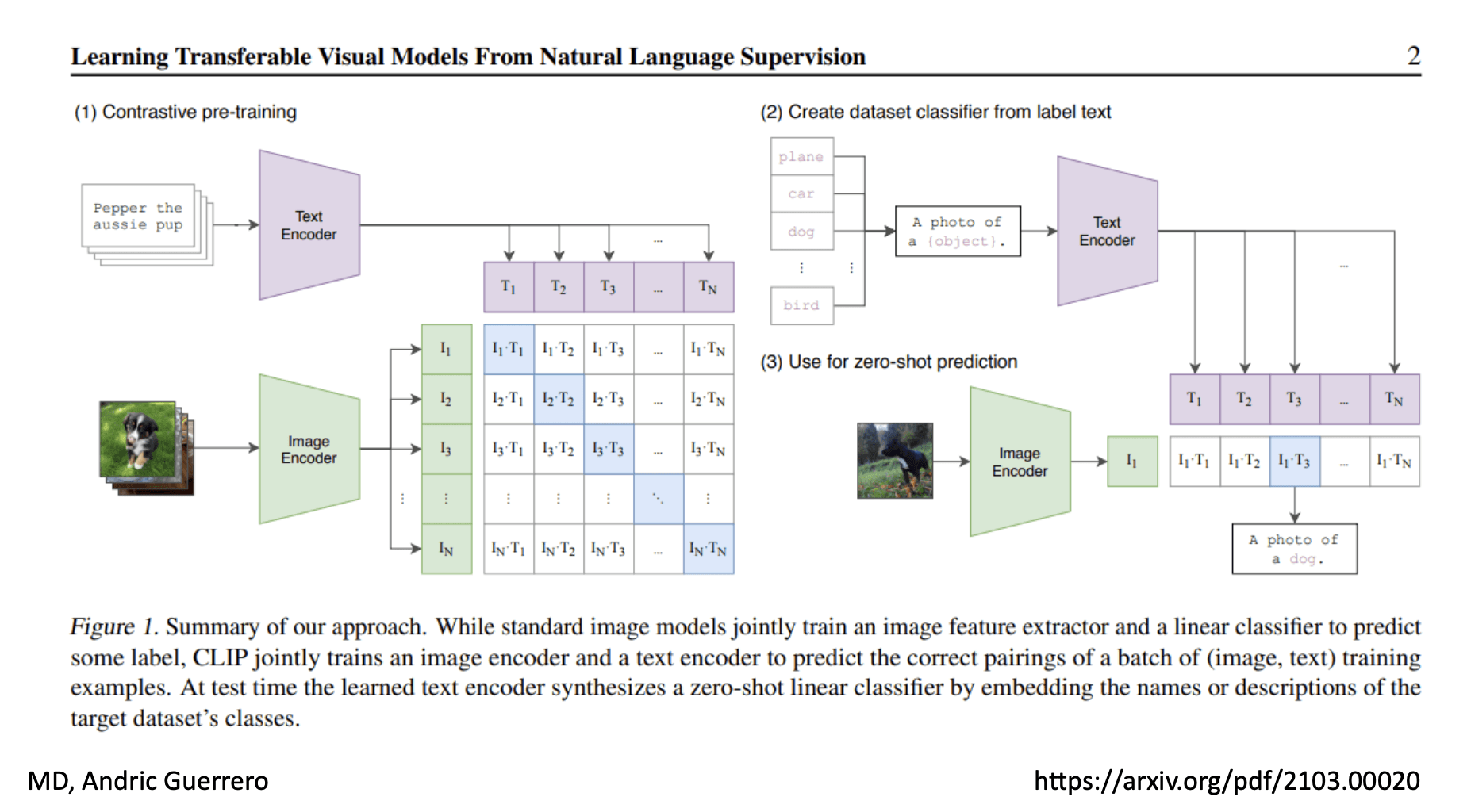
2. Deep Dive: Modelos que definen el estándarComo científico de IA analice cómo arquitecturas específicas están siendo adaptadas al dominio médico, las mostré a mis alumnos de postgrado, quienes pudieron evaluar el desempeño de estos modelos en medicina.
Experimentamos varias veces, y bueno aquí un resumen:
CLIP y SigLIP: CLIP utiliza una pérdida contrastiva tipo softmax, mientras que SigLIP propone una pérdida sigmoidal por pares. Esta última es más eficiente en memoria y estable para entrenamientos con batches más pequeños, lo que la convierte en una opción robusta para pipelines modernos en salud.
BLIP-2 y el Q-Former: Para evitar el altísimo costo de entrenar modelos gigantes de extremo a extremo, BLIP-2 utiliza un "puente" llamado Q-Former. Este componente extrae un conjunto pequeño de tokens visuales informativos de un encoder congelado y los traduce al espacio del LLM, optimizando el rendimiento con menos recursos computacionales.
Flamingo: Es fundamental por su capacidad few-shot. Mediante capas de gated cross-attention y un Perceiver Resampler, el modelo puede aprender a realizar tareas complejas (como describir una biopsia) con solo unos pocos ejemplos incluidos en el prompt.
LLaVA / Med-LLaVA: Utiliza una arquitectura más simple basada en un proyector (MLP o lineal) para pasar las características visuales directamente como tokens al LLM. Su éxito radica en un buen ajuste instruccional con pares imagen-texto.
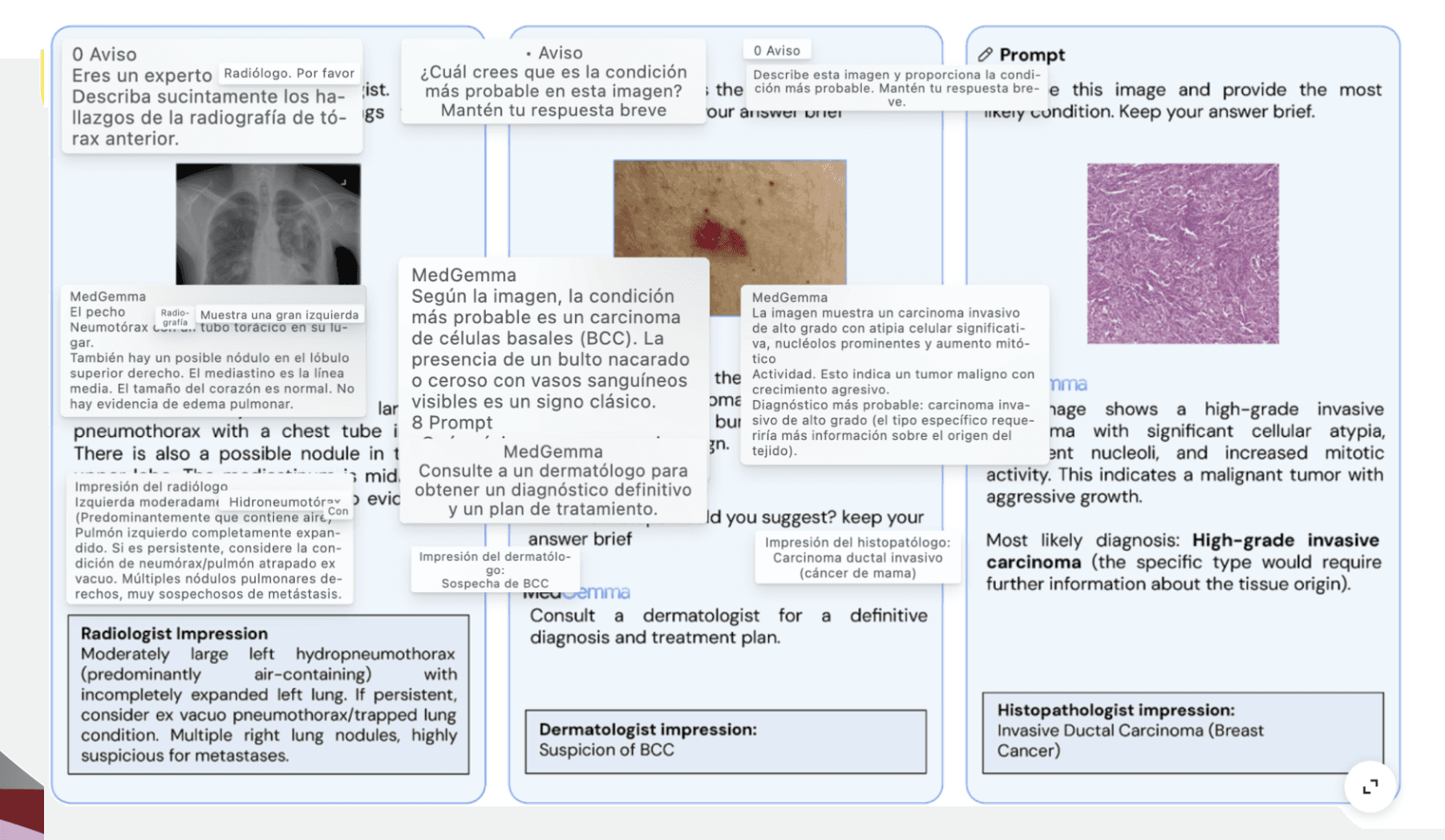
3. Aplicaciones Clínicas: Radiología y Patología DigitalLa implementación de estos modelos varía según la especialidad:
A) Radiología: Se enfoca en el reporte automático (image-to-report) utilizando datasets como MIMIC-CXR e IU-Xray. El triage y el retrieval semántico permiten priorizar casos de alto riesgo mediante la detección de similitudes con descripciones textuales predefinidas.
B) Patología Digital: Dada la naturaleza gigapíxel de las imágenes de portaobjetos completos (WSI), el enfoque se basa en la extracción de tiles o parches. El modelo realiza un grounding espacial, lo que significa que no solo identifica una patología (ej. carcinoma), sino que puede señalar la región exacta y el patrón que justifica el diagnóstico mediante mapas de atención o heatmaps. Herramientas como PathVQA están permitiendo que los patólogos interactúen con las láminas mediante preguntas y respuestas sobre morfología celular.
4. La Frontera Actual: MedMO y MedGemma 1.5
Hacia principios de 2026, estamos viendo el surgimiento de modelos "nativos" médicos:
MedMO: Un modelo que enfatiza el grounding espacial y el razonamiento paso a paso. Utiliza una receta de entrenamiento multi-etapa que incluye aprendizaje por refuerzo con recompensas verificables para asegurar que las cajas de delimitación diagnósticas sean precisas.
MedGemma 1.5: La actualización de Google que mejora significativamente el soporte para imágenes 2D, registros médicos y voz (MedASR). Ha demostrado mejoras críticas en tareas de localización anatómica y extracción de datos estructurados de informes de laboratorio.
5. Desafíos y Limitaciones Clínicas
No podemos ignorar los riesgos. Las limitaciones clave incluyen:
Shift de dominio: El rendimiento cae al cambiar de hospital o equipo.
Ruido en los datos: Las etiquetas extraídas por NLP suelen tener incertidumbre.
Alucinaciones: Los modelos generativos pueden redactar reportes clínicos muy convincentes pero factualmente incorrectos.
Evaluación: Métricas como BLEU o ROUGE no capturan la seguridad clínica necesaria.
Conclusión y Perspectivas
La IA multimodal no reemplazará al médico, pero el médico que use estas herramientas tendrá una ventaja competitiva sin precedentes en precisión y eficiencia. El futuro reside en modelos más integrados y en la curación de datasets de alta calidad, que siguen siendo el verdadero "secreto" detrás del rendimiento de frontera.
Para profundizar en estos temas y acceder a demostraciones de código, pueden visitar mis recursos en andricpath.com
Nota: Si desean aprender a usar estos modelos, a testearlos o entender la tecnología detrás, anímense a recibir clases privadas, estaremos gustosos de colocarlos en la lista de espera!